В мире быстро развивающихся технологий искусственного интеллекта качество модели определяет успех всего проекта. Представьте инструмент, который может за считанные минуты провести комплексную оценку вашей ИИ-системы, выявить слабые места и предоставить детальную аналитику производительности. Именно таким инструментом является наша платформа на основе DeepEval.
Что такое DeepEval и почему это важно?
DeepEval — это мощная библиотека для автоматического тестирования и оценки производительности языковых моделей. В отличие от традиционных методов оценки, DeepEval предоставляет комплексный анализ различных аспектов работы ИИ: от точности ответов до этических соображений.
Наш инструмент интегрирует возможности DeepEval в удобный веб-интерфейс, позволяя разработчикам и исследователям получать детальные отчеты о качестве своих моделей без необходимости глубокого погружения в техническую документацию.
Q-BENCH EVALUATION
Запуск тестов на вашей системе...
8/8 [100%] Завершено за 2:14
Ключевые преимущества нашего инструмента
- Комплексная оценка: Анализ более 15 ключевых метрик качества ИИ
- Автоматизированное тестирование: Без необходимости ручной настройки
- Визуальная аналитика: Интуитивно понятные графики и диаграммы
- Быстрые результаты: Полный анализ за несколько минут
- Экспорт отчетов: Детальные PDF-отчеты для команды
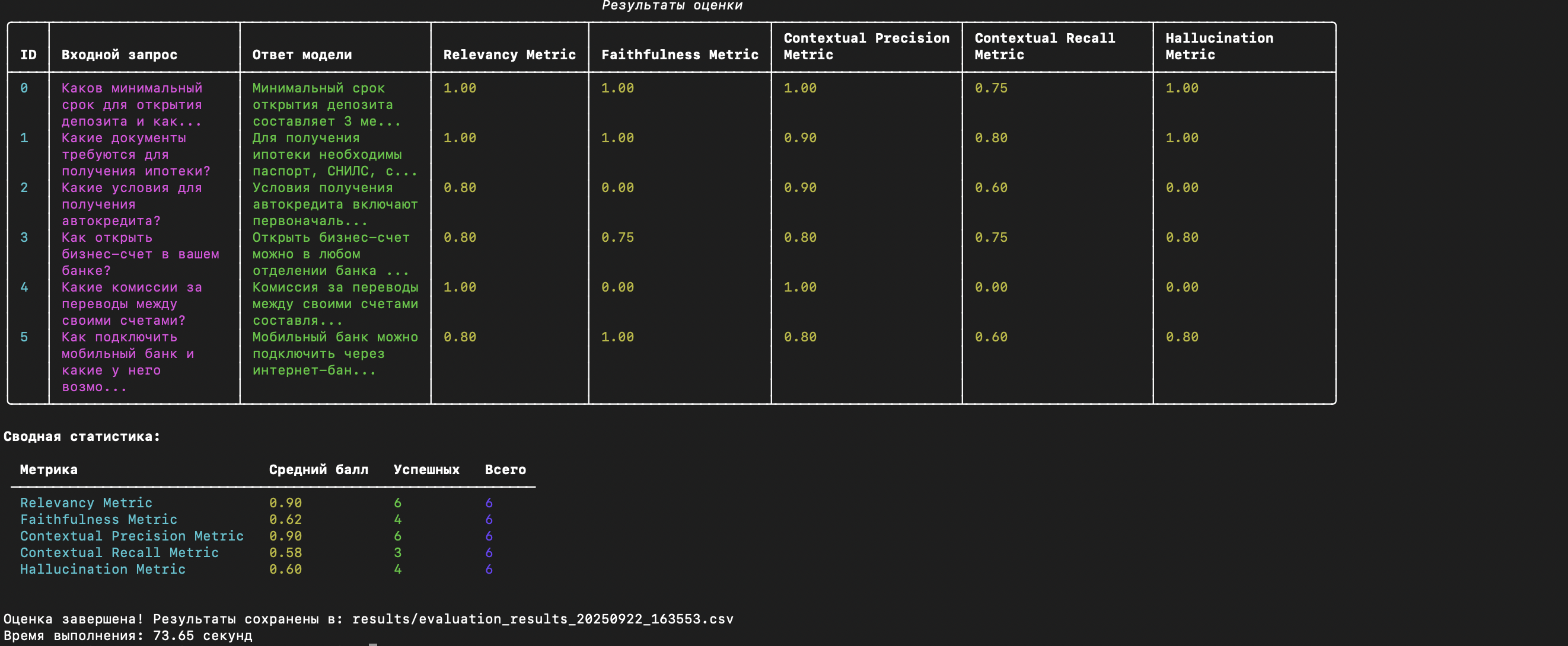
Примеры результатов Q-Bench в действии
Посмотрите, как выглядят результаты комплексной оценки ИИ-модели с помощью нашего инструмента. Детальная аналитика, цветовые индикаторы и понятные метрики помогают быстро понять качество вашей модели.
Детальный отчет по метрикам
Полная разбивка производительности модели по всем ключевым показателям

Сводная аналитика
Визуализация общих показателей и проблемных областей для быстрой оценки
Что вы получаете с Q-Bench:
Быстрый анализ
Полная оценка модели за несколько минут
Наглядность
Интуитивно понятные графики и таблицы
Экспорт данных
PDF и CSV отчеты для команды
Надежность
Проверенные метрики и алгоритмы
Метрики оценки в нашем инструменте
Наша платформа оценивает ИИ-модели по множеству критически важных метрик:
Основные метрики качества:
- Точность (Accuracy): Процент правильных ответов модели
- Релевантность: Соответствие ответов заданным вопросам
- Полнота: Насколько исчерпывающими являются ответы
- Последовательность: Стабильность качества ответов
Метрики безопасности:
- Обнаружение галлюцинаций: Выявление ложной информации
- Токсичность: Анализ потенциально вредного контента
- Предвзятость: Оценка справедливости модели
- Защита от атак: Устойчивость к попыткам взлома
Как интерпретировать результаты
Результаты представлены в виде удобной таблицы с цветовой индикацией:
- 🟢 Зеленый (80-100%): Отличная производительность
- 🟡 Желтый (60-79%): Требует внимания
- 🔴 Красный (0-59%): Критические проблемы
Следующие шаги после тестирования
После получения результатов оценки рекомендуем:
- Проанализировать области с низкими оценками
- Приоритизировать улучшения по критичности
- Реализовать изменения в модели или данных
- Провести повторное тестирование
- Мониторить производительность в продакшене
Наш инструмент на базе DeepEval поможет вам создать надежную, безопасную и высокопроизводительную ИИ-систему, которая будет соответствовать самым высоким стандартам качества.
Готовы протестировать вашу ИИ-модель?
Получите комплексный анализ качества с помощью Q-Bench. Первые 30 вопросов — бесплатно!
Начать тестирование